Comment extraire des données d’un PDF manuellement et de manière automatisée

Sommaire :
Apprenez à extraire des données d’un PDF, manuellement ou automatiquement. Méthodes gratuites et simples fournies.
Navigation
Extraire des données de PDF
Extraire des données de fichiers PDF pose souvent des défis tels que le formatage fixe, le texte non sélectionnable (surtout dans les documents scannés), et la perte de la structure des données.
Pour surmonter ces problèmes, utilisez la reconnaissance optique de caractères (OCR) pour les PDF scannés, des logiciels spécialisés pour l’extraction de tableaux, et des outils de conversion pour des formats modifiables comme Excel. Apprenez à partir de ce guide sur 3 méthodes faciles pour cela.
👉 Pour gagner du temps, téléchargez gratuitement PDFgear, PDFgear est le meilleur extracteur de données gratuit de PDF à Excel.
Extraire des tableaux d’un PDF avec Tabula
Tabula est un outil gratuit et open-source conçu pour extraire des tableaux de fichiers PDF. Il permet aux utilisateurs de sélectionner manuellement les régions des tableaux pour une extraction précise.
Idéal pour convertir des tableaux PDF en Excel ou CSV, Tabula est excellent pour des tâches manuelles à petite échelle mais moins adapté pour des extractions automatisées de grande envergure. Sa principale limitation est l’incapacité de traiter le texte OCR des documents scannés.
Pour extraire des tableaux d’un PDF avec Tabula :
Étape 1. Téléchargez et installez Tabula depuis le site officiel, puis lancez-le sur votre appareil.
Télécharger et Installer Tabula
Étape 2. Cliquez sur ‘Parcourir’ pour sélectionner le fichier PDF à partir duquel vous souhaitez extraire des données. Cliquez sur ‘Soumettre’ après avoir choisi le fichier.
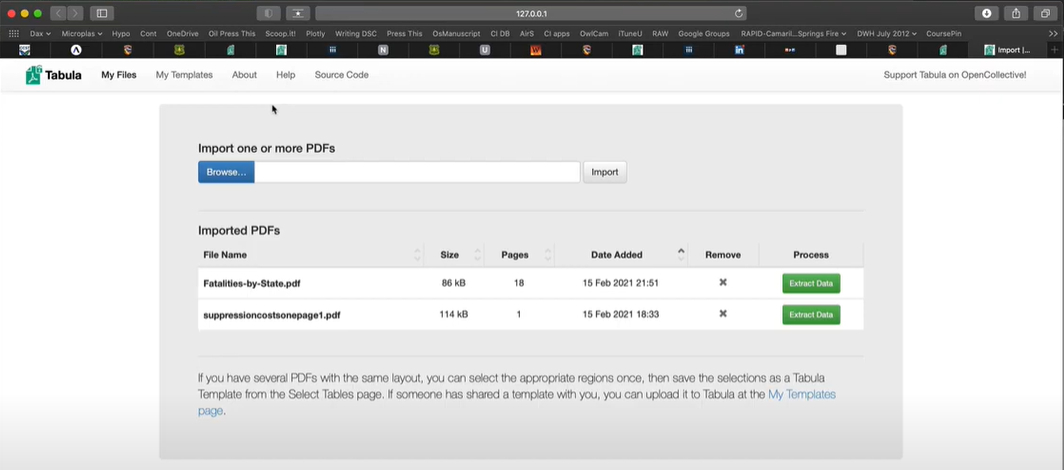
Cliquez sur Parcourir dans Tabula
Étape 3. Le PDF sera affiché dans l’interface de Tabula. Cliquez sur Autodétecter les tableaux ou faites glisser votre souris pour sélectionner la zone du tableau que vous souhaitez extraire.
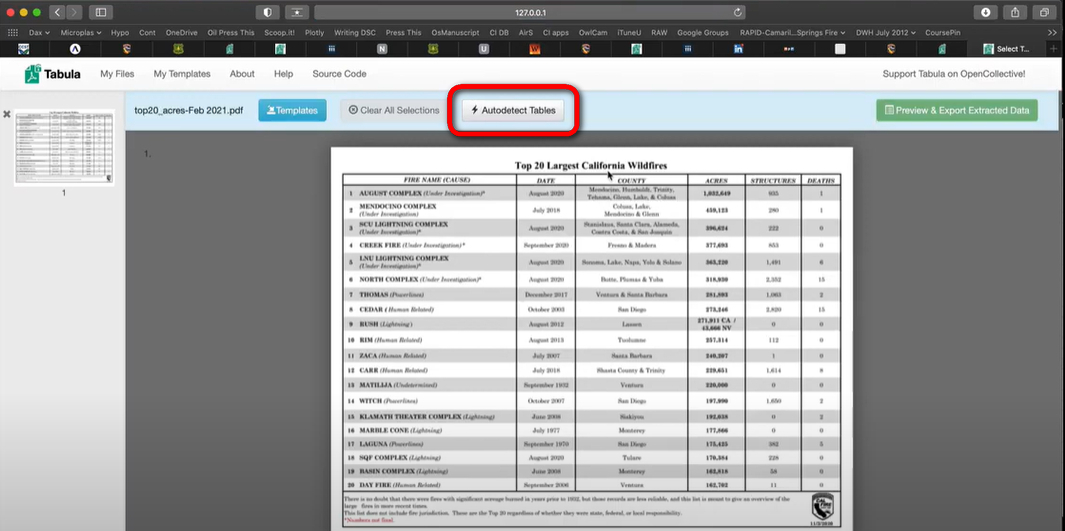
Autodétecter les Tableaux dans Tabula
Étape 4. Après sélection, cliquez sur ‘Aperçu & Exporter les Données Extraites.’ Vérifiez l’aperçu pour vous assurer de la correcte extraction des données.

Aperçu et Exportation dans Tabula
Étape 5. Cliquez sur ‘Exporter’ et choisissez le format préféré (CSV, TSV, JSON) pour sauvegarder le tableau extrait. Enfin, cliquez sur ‘Enregistrer’.
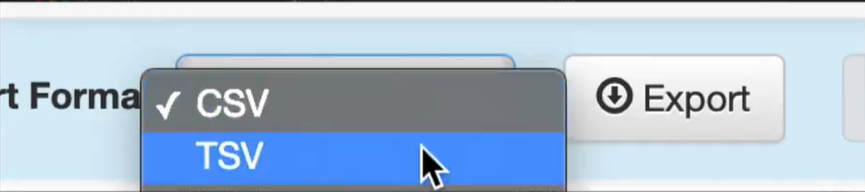
Définir le Format d’Exportation dans Tabula
Extraire des données de PDF avec Adobe Acrobat Pro
Adobe Acrobat Pro est un outil robuste pour extraire des données de fichiers PDF, reconnu pour sa précision et son efficacité. Il excelle dans la gestion de différents types de documents et est capable de convertir des PDF en divers formats éditables. Idéal pour les professionnels, il intègre des fonctionnalités avancées comme l’OCR pour les documents scannés.
Cependant, il peut être plus complexe et coûteux (l’abonnement Pro) pour des tâches d’extraction simples.
Pour extraire des tableaux d’un PDF à l’aide d’Adobe Acrobat, suivez ces étapes :
Étape 1. Téléchargez et installez Adobe Acrobat Reader sur votre appareil.
Étape 2. Ouvrez le PDF dans Adobe Acrobat DC. Allez dans ‘Outils’ et sélectionnez ‘Exporter le PDF’.
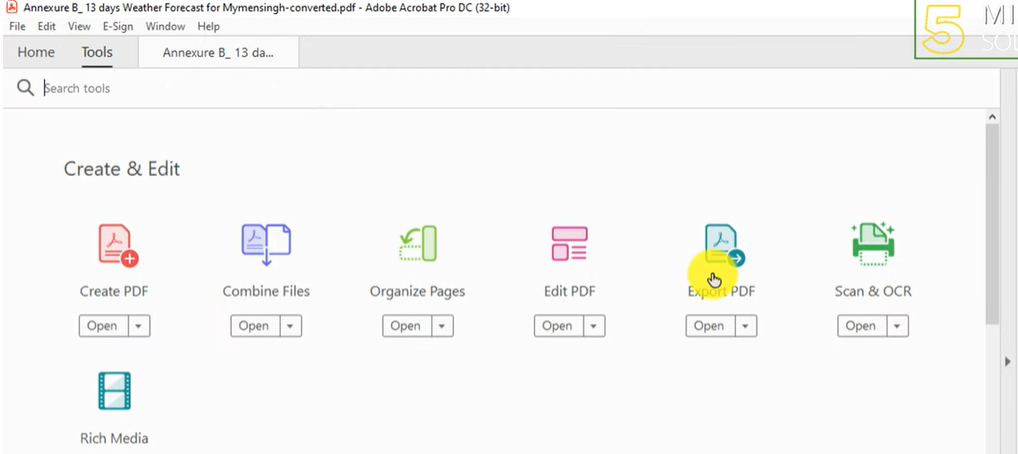
Cliquer sur Exporter le PDF dans Adobe
Étape 3. Choisissez ‘Feuille de calcul’ comme format d’exportation, puis sélectionnez ‘Classeur Microsoft Excel’.
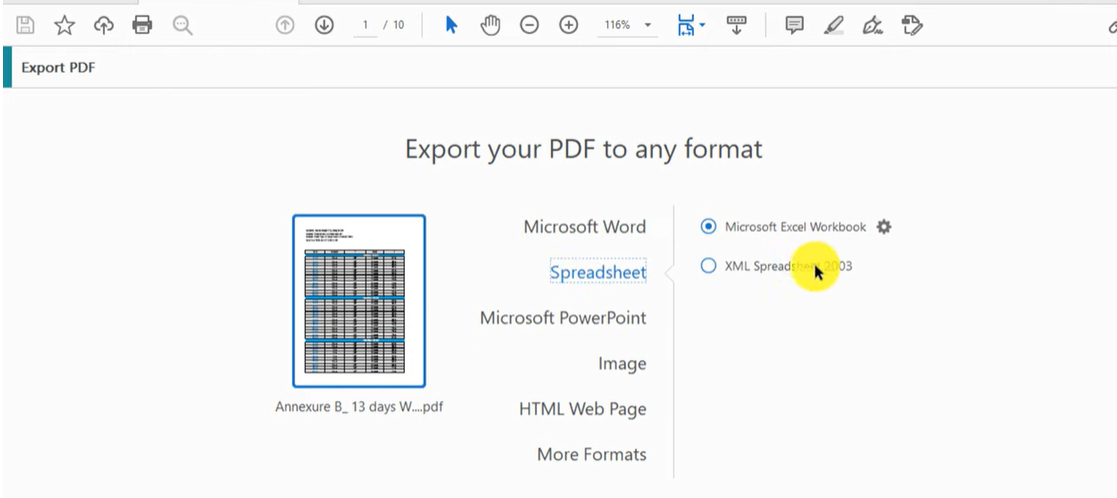
Exporter le PDF dans Adobe
Étape 4. Cliquez sur ‘Exporter’. Si votre PDF contient du texte scanné, Acrobat exécutera automatiquement la reconnaissance de texte.
Étape 5. Nommez votre fichier et choisissez l’emplacement pour l’enregistrer.
Étape 6. Cliquez sur ‘Enregistrer’. Ce processus convertit tout le PDF en fichier Excel, y compris les tableaux.
Extraire les données de PDF vers une feuille de calcul Excel gratuitement
PDFgear est un convertisseur de PDF complet qui vous permet d’extraire des données de PDF en convertissant des PDF non modifiables ou scannés en formats de documents éditables tels que Microsoft Word, Excel et TXT.
Propulsé par la technologie OCR, les conversions de fichiers PDFgear assurent la précision de l’extraction des données.
PDFgear est entièrement gratuit à utiliser et fonctionne sur Windows, Mac et iOS. Procurez-le-vous et commençons !
Gratuit pour extraire des tableaux et des données de documents PDF et scannés en Microsoft Word, Excel et TXT modifiables.
Étape 1. Téléchargez PDFgear sur votre appareil et lancez-le une fois installé.
Étape 2. Rendez-vous dans la boîte à outils Convertir depuis PDF et sélectionnez l’outil convertisseur PDF en Excel.
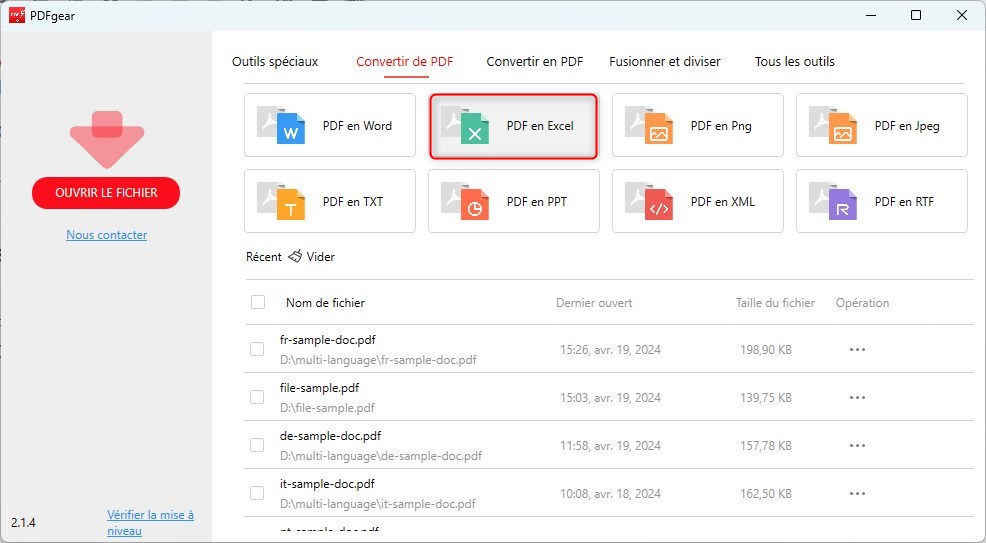
PDFgear PDF en Excel
Étape 3. Cliquez sur Ajouter un fichier pour importer un ou plusieurs fichiers PDF à extraire en même temps.
Étape 4. Spécifiez les plages de pages et le dossier de fichier de sortie, et cliquez sur Convertir pour démarrer la conversion.
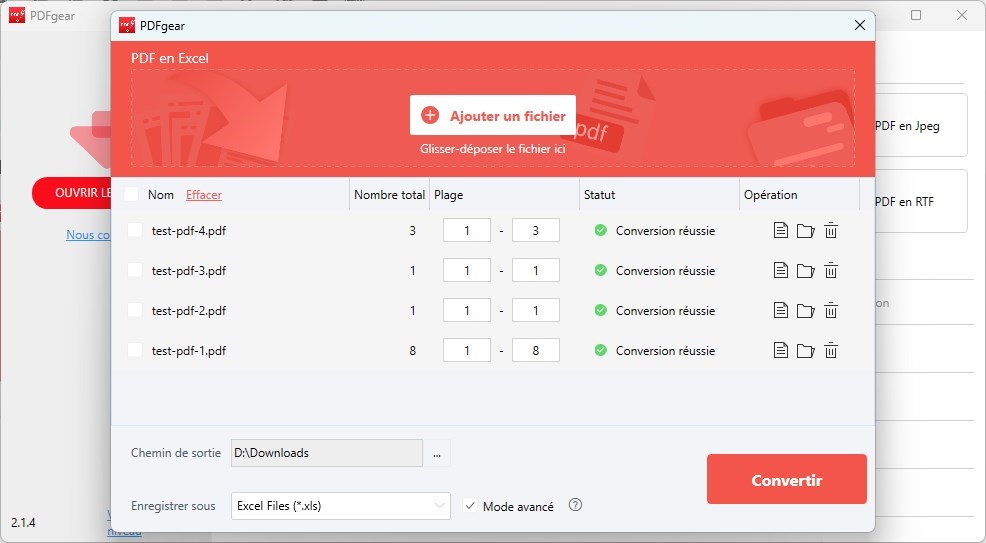
Extraire les données PDF en Excel
Extraire des données de PDF à l’aide de l’IA
L’intelligence artificielle d’aujourd’hui améliore considérablement l’efficacité des personnes travaillant avec des documents, et aide même à automatiser l’extraction de données de PDF. Pour extraire des données de PDF à l’aide de l’IA, voici les méthodes les plus fiables :
- Summariseurs de PDF IA : Utilisez un summariseur IA comme Chatbot PDFgear pour comprendre facilement les PDFs
- Analyseurs de PDF basés sur l’apprentissage automatique : Conçus pour comprendre des agencements complexes et extraire les données en conséquence.
- Services IA de compréhension de documents : Des services comme Google Cloud’s Document AI ou Amazon Textract analysent la structure et le contenu des documents.
- Modèles IA personnalisés : Construisez des modèles personnalisés avec des bibliothèques d’apprentissage automatique (comme TensorFlow ou PyTorch) pour extraire des types de données spécifiques.
- Outils de Traitement Automatique du Langage Naturel (TALN) : Pour extraire et analyser des données textuelles dans les PDFs.
Foire aux questions
Est-il possible d’extraire des emails à partir d’un PDF scanné ?
Oui, il est possible d’extraire des emails de PDFs scannés en utilisant la technologie OCR. L’OCR peut convertir le texte basé sur image des PDFs scannés en texte éditable et recherchable, qui peut ensuite être utilisé pour trouver et extraire des adresses email.
Quelle est la précision de l’extraction des emails à partir de PDFs ?
La précision dépend de la qualité du PDF et de l’efficacité de l’outil d’extraction. Les PDFs de haute qualité, basés sur texte, donnent généralement de meilleurs résultats, tandis que les PDFs scannés ou ceux avec des agencements complexes peuvent entraîner une précision plus faible.
Est-il légal d’extraire des emails de PDFs ?
La légalité de l’extraction d’emails de PDFs dépend de la source des PDFs et de l’utilisation prévue des emails. Il est important de s’assurer que vous avez le droit d’accéder et d’utiliser les informations dans les PDFs, surtout à des fins commerciales.
Conclusion
Le choix de l’outil dépend des besoins spécifiques, comme le volume de données, le type de PDF (scanné ou basé sur texte), et le format de sortie souhaité. Choisissez-en un selon vos besoins, et suivez le guide pour commencer !